|
|
@@ -0,0 +1,1081 @@
|
|
|
+# coding=utf-8
|
|
|
+
|
|
|
+import json
|
|
|
+import os
|
|
|
+import time
|
|
|
+import random
|
|
|
+from datetime import datetime
|
|
|
+import webbrowser
|
|
|
+from typing import Dict, List, Tuple, Optional, Union
|
|
|
+
|
|
|
+import requests
|
|
|
+import pytz
|
|
|
+
|
|
|
+# 配置常量
|
|
|
+CONFIG = {
|
|
|
+ "FEISHU_SEPARATOR": "==============================", # 飞书消息中,每个频率词之间的分割线,注意,其它类型的分割线可能会被飞书过滤而显示怪异
|
|
|
+ "REQUEST_INTERVAL": 1000, # 毫秒
|
|
|
+ "FEISHU_REPORT_TYPE": "daily", # 可选: "current", "daily", "both"
|
|
|
+ "RANK_THRESHOLD": 5, # 排名阈值,决定使用【】还是[]的界限
|
|
|
+ "USE_PROXY": False, # 是否启用本地代理
|
|
|
+ "DEFAULT_PROXY": "http://127.0.0.1:10086",
|
|
|
+ "CONTINUE_WITHOUT_FEISHU": False, # 控制是否在没有飞书webhook URL时继续执行爬虫, 如果True ,会依然进行爬虫行为,会在github上持续的生成爬取的新闻数据
|
|
|
+ "FEISHU_WEBHOOK_URL": "", # 飞书机器人的webhook URL,大概长这样:https://www.feishu.cn/flow/api/trigger-webhook/xxxx, 默认为空,推荐通过GitHub Secrets设置
|
|
|
+}
|
|
|
+
|
|
|
+
|
|
|
+class TimeHelper:
|
|
|
+ """时间相关的辅助功能"""
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def get_beijing_time() -> datetime:
|
|
|
+ """获取北京时间"""
|
|
|
+ return datetime.now(pytz.timezone("Asia/Shanghai"))
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def format_date_folder() -> str:
|
|
|
+ """返回日期文件夹名称格式"""
|
|
|
+ return TimeHelper.get_beijing_time().strftime("%Y年%m月%d日")
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def format_time_filename() -> str:
|
|
|
+ """返回时间文件名格式"""
|
|
|
+ return TimeHelper.get_beijing_time().strftime("%H时%M分")
|
|
|
+
|
|
|
+
|
|
|
+class FileHelper:
|
|
|
+ """文件操作相关的辅助功能"""
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def ensure_directory_exists(directory: str) -> None:
|
|
|
+ """确保目录存在,如果不存在则创建"""
|
|
|
+ if not os.path.exists(directory):
|
|
|
+ os.makedirs(directory)
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def get_output_path(subfolder: str, filename: str) -> str:
|
|
|
+ """获取输出文件路径"""
|
|
|
+ date_folder = TimeHelper.format_date_folder()
|
|
|
+ output_dir = os.path.join("output", date_folder, subfolder)
|
|
|
+ FileHelper.ensure_directory_exists(output_dir)
|
|
|
+ return os.path.join(output_dir, filename)
|
|
|
+
|
|
|
+
|
|
|
+class DataFetcher:
|
|
|
+ """数据获取相关功能"""
|
|
|
+
|
|
|
+ def __init__(self, proxy_url: Optional[str] = None):
|
|
|
+ self.proxy_url = proxy_url
|
|
|
+
|
|
|
+ def fetch_data(
|
|
|
+ self,
|
|
|
+ id_info: Union[str, Tuple[str, str]],
|
|
|
+ max_retries: int = 2,
|
|
|
+ min_retry_wait: int = 3,
|
|
|
+ max_retry_wait: int = 5,
|
|
|
+ ) -> Tuple[Optional[str], str, str]:
|
|
|
+ """
|
|
|
+ 同步获取指定ID的数据,失败时进行重试
|
|
|
+ 接受'success'和'cache'两种状态,其他状态才会触发重试
|
|
|
+
|
|
|
+ Args:
|
|
|
+ id_info: ID信息,可以是ID字符串或(ID, 别名)元组
|
|
|
+ max_retries: 最大重试次数
|
|
|
+ min_retry_wait: 最小重试等待时间(秒)
|
|
|
+ max_retry_wait: 最大重试等待时间(秒)
|
|
|
+
|
|
|
+ Returns:
|
|
|
+ (响应数据, ID, 别名)元组,如果请求失败则响应数据为None
|
|
|
+ """
|
|
|
+ # 处理ID和别名
|
|
|
+ if isinstance(id_info, tuple):
|
|
|
+ id_value, alias = id_info
|
|
|
+ else:
|
|
|
+ id_value = id_info
|
|
|
+ alias = id_value
|
|
|
+
|
|
|
+ url = f"https://newsnow.busiyi.world/api/s?id={id_value}&latest"
|
|
|
+
|
|
|
+ # 设置代理
|
|
|
+ proxies = None
|
|
|
+ if self.proxy_url:
|
|
|
+ proxies = {"http": self.proxy_url, "https": self.proxy_url}
|
|
|
+
|
|
|
+ # 添加随机性模拟真实用户
|
|
|
+ headers = {
|
|
|
+ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
|
|
|
+ "Accept": "application/json, text/plain, */*",
|
|
|
+ "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7",
|
|
|
+ "Connection": "keep-alive",
|
|
|
+ "Cache-Control": "no-cache",
|
|
|
+ }
|
|
|
+
|
|
|
+ retries = 0
|
|
|
+ while retries <= max_retries:
|
|
|
+ try:
|
|
|
+ print(
|
|
|
+ f"正在请求 {id_value} 数据... (尝试 {retries + 1}/{max_retries + 1})"
|
|
|
+ )
|
|
|
+ response = requests.get(
|
|
|
+ url, proxies=proxies, headers=headers, timeout=10
|
|
|
+ )
|
|
|
+ response.raise_for_status() # 检查HTTP状态码
|
|
|
+
|
|
|
+ # 解析JSON并检查响应状态
|
|
|
+ data_text = response.text
|
|
|
+ data_json = json.loads(data_text)
|
|
|
+
|
|
|
+ # 修改状态检查逻辑:接受success和cache两种状态
|
|
|
+ status = data_json.get("status", "未知")
|
|
|
+ if status not in ["success", "cache"]:
|
|
|
+ raise ValueError(f"响应状态异常: {status}")
|
|
|
+
|
|
|
+ # 记录状态信息
|
|
|
+ status_info = "最新数据" if status == "success" else "缓存数据"
|
|
|
+ print(f"成功获取 {id_value} 数据({status_info})")
|
|
|
+ return data_text, id_value, alias
|
|
|
+
|
|
|
+ except Exception as e:
|
|
|
+ retries += 1
|
|
|
+ if retries <= max_retries:
|
|
|
+ # 计算重试等待时间:基础3-5秒,每次重试增加1-2秒
|
|
|
+ base_wait = random.uniform(min_retry_wait, max_retry_wait)
|
|
|
+ additional_wait = (retries - 1) * random.uniform(1, 2)
|
|
|
+ wait_time = base_wait + additional_wait
|
|
|
+
|
|
|
+ print(
|
|
|
+ f"请求 {id_value} 失败: {e}. 将在 {wait_time:.2f} 秒后重试..."
|
|
|
+ )
|
|
|
+ time.sleep(wait_time)
|
|
|
+ else:
|
|
|
+ print(f"请求 {id_value} 失败: {e}. 已达到最大重试次数。")
|
|
|
+ return None, id_value, alias
|
|
|
+ return None, id_value, alias
|
|
|
+
|
|
|
+ def crawl_websites(
|
|
|
+ self,
|
|
|
+ ids_list: List[Union[str, Tuple[str, str]]],
|
|
|
+ request_interval: int = CONFIG["REQUEST_INTERVAL"],
|
|
|
+ ) -> Tuple[Dict, Dict, List]:
|
|
|
+ """
|
|
|
+ 爬取多个网站的数据,使用同步请求
|
|
|
+
|
|
|
+ Args:
|
|
|
+ ids_list: ID列表,每个元素可以是ID字符串或(ID, 别名)元组
|
|
|
+ request_interval: 请求间隔(毫秒)
|
|
|
+
|
|
|
+ Returns:
|
|
|
+ (results, id_to_alias, failed_ids)元组
|
|
|
+ """
|
|
|
+ results = {}
|
|
|
+ id_to_alias = {}
|
|
|
+ failed_ids = []
|
|
|
+
|
|
|
+ for i, id_info in enumerate(ids_list):
|
|
|
+ # 处理ID和别名
|
|
|
+ if isinstance(id_info, tuple):
|
|
|
+ id_value, alias = id_info
|
|
|
+ else:
|
|
|
+ id_value = id_info
|
|
|
+ alias = id_value
|
|
|
+
|
|
|
+ # 添加到ID-别名映射
|
|
|
+ id_to_alias[id_value] = alias
|
|
|
+
|
|
|
+ # 发送请求
|
|
|
+ response, _, _ = self.fetch_data(id_info)
|
|
|
+
|
|
|
+ # 处理响应
|
|
|
+ if response:
|
|
|
+ try:
|
|
|
+ data = json.loads(response)
|
|
|
+ # 获取标题列表,同时记录排名
|
|
|
+ results[id_value] = {}
|
|
|
+ for index, item in enumerate(data.get("items", []), 1):
|
|
|
+ title = item["title"]
|
|
|
+ if title in results[id_value]:
|
|
|
+ results[id_value][title].append(index)
|
|
|
+ else:
|
|
|
+ results[id_value][title] = [index]
|
|
|
+ except json.JSONDecodeError:
|
|
|
+ print(f"解析 {id_value} 的响应失败,不是有效的JSON")
|
|
|
+ failed_ids.append(id_value)
|
|
|
+ except Exception as e:
|
|
|
+ print(f"处理 {id_value} 数据时出错: {e}")
|
|
|
+ failed_ids.append(id_value)
|
|
|
+ else:
|
|
|
+ failed_ids.append(id_value)
|
|
|
+
|
|
|
+ # 添加间隔时间,除非是最后一个请求
|
|
|
+ if i < len(ids_list) - 1:
|
|
|
+ # 添加一些随机性到间隔时间
|
|
|
+ actual_interval = request_interval + random.randint(-10, 20)
|
|
|
+ actual_interval = max(50, actual_interval) # 确保至少50毫秒
|
|
|
+ print(f"等待 {actual_interval} 毫秒后发送下一个请求...")
|
|
|
+ time.sleep(actual_interval / 1000)
|
|
|
+
|
|
|
+ print(f"\n请求总结:")
|
|
|
+ print(f"- 成功获取数据的ID: {list(results.keys())}")
|
|
|
+ print(f"- 请求失败的ID: {failed_ids}")
|
|
|
+
|
|
|
+ return results, id_to_alias, failed_ids
|
|
|
+
|
|
|
+
|
|
|
+class DataProcessor:
|
|
|
+ """数据处理相关功能"""
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def save_titles_to_file(results: Dict, id_to_alias: Dict, failed_ids: List) -> str:
|
|
|
+ """将标题保存到文件,包括失败的请求信息"""
|
|
|
+ file_path = FileHelper.get_output_path(
|
|
|
+ "txt", f"{TimeHelper.format_time_filename()}.txt"
|
|
|
+ )
|
|
|
+
|
|
|
+ with open(file_path, "w", encoding="utf-8") as f:
|
|
|
+ # 先写入成功获取的数据
|
|
|
+ for id_value, title_data in results.items():
|
|
|
+ display_name = id_to_alias.get(id_value, id_value)
|
|
|
+ f.write(f"{display_name}\n")
|
|
|
+ for i, (title, ranks) in enumerate(title_data.items(), 1):
|
|
|
+ rank_str = ",".join(map(str, ranks))
|
|
|
+ f.write(f"{i}. {title} (排名:{rank_str})\n")
|
|
|
+ f.write("\n")
|
|
|
+
|
|
|
+ # 如果有失败的请求,写入失败信息
|
|
|
+ if failed_ids:
|
|
|
+ f.write("==== 以下ID请求失败 ====\n")
|
|
|
+ for id_value in failed_ids:
|
|
|
+ display_name = id_to_alias.get(id_value, id_value)
|
|
|
+ f.write(f"{display_name} (ID: {id_value})\n")
|
|
|
+
|
|
|
+ return file_path
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def load_frequency_words(
|
|
|
+ frequency_file: str = "frequency_words.txt",
|
|
|
+ ) -> Tuple[List[List[str]], List[str]]:
|
|
|
+ """
|
|
|
+ 加载频率词和过滤词,处理关联词
|
|
|
+
|
|
|
+ Returns:
|
|
|
+ (word_groups, filter_words)元组
|
|
|
+ """
|
|
|
+ if not os.path.exists(frequency_file):
|
|
|
+ print(f"频率词文件 {frequency_file} 不存在")
|
|
|
+ return [], []
|
|
|
+
|
|
|
+ with open(frequency_file, "r", encoding="utf-8") as f:
|
|
|
+ content = f.read()
|
|
|
+
|
|
|
+ # 按双空行分割不同的词组
|
|
|
+ word_groups = [
|
|
|
+ group.strip() for group in content.split("\n\n") if group.strip()
|
|
|
+ ]
|
|
|
+
|
|
|
+ # 处理每个词组
|
|
|
+ processed_groups = []
|
|
|
+ filter_words = [] # 用于存储过滤词
|
|
|
+
|
|
|
+ for group in word_groups:
|
|
|
+ words = [word.strip() for word in group.split("\n") if word.strip()]
|
|
|
+
|
|
|
+ # 分离频率词和过滤词
|
|
|
+ group_frequency_words = []
|
|
|
+
|
|
|
+ for word in words:
|
|
|
+ if word.startswith("!"):
|
|
|
+ # 去掉感叹号,添加到过滤词列表
|
|
|
+ filter_words.append(word[1:])
|
|
|
+ else:
|
|
|
+ # 正常的频率词
|
|
|
+ group_frequency_words.append(word)
|
|
|
+
|
|
|
+ # 只有当词组中包含频率词时才添加到结果中
|
|
|
+ if group_frequency_words:
|
|
|
+ processed_groups.append(group_frequency_words)
|
|
|
+
|
|
|
+ return processed_groups, filter_words
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def read_all_today_titles() -> Tuple[Dict, Dict, Dict]:
|
|
|
+ """
|
|
|
+ 读取当天所有txt文件的标题,并按来源合并,去除重复,记录时间和出现次数
|
|
|
+
|
|
|
+ Returns:
|
|
|
+ (all_results, id_to_alias, title_info)元组
|
|
|
+ """
|
|
|
+ date_folder = TimeHelper.format_date_folder()
|
|
|
+ txt_dir = os.path.join("output", date_folder, "txt")
|
|
|
+
|
|
|
+ if not os.path.exists(txt_dir):
|
|
|
+ print(f"今日文件夹 {txt_dir} 不存在")
|
|
|
+ return {}, {}, {}
|
|
|
+
|
|
|
+ all_results = {} # 所有源的所有标题 {source_id: {title: [ranks]}}
|
|
|
+ id_to_alias = {} # ID到别名的映射
|
|
|
+ title_info = (
|
|
|
+ {}
|
|
|
+ ) # 标题信息 {source_id: {title: {"first_time": 首次时间, "last_time": 最后时间, "count": 出现次数, "ranks": [排名列表]}}}
|
|
|
+
|
|
|
+ # 读取所有txt文件,按时间排序确保早的时间优先处理
|
|
|
+ files = sorted([f for f in os.listdir(txt_dir) if f.endswith(".txt")])
|
|
|
+
|
|
|
+ for file in files:
|
|
|
+ # 从文件名提取时间信息 (例如 "12时34分.txt")
|
|
|
+ time_info = file.replace(".txt", "")
|
|
|
+
|
|
|
+ file_path = os.path.join(txt_dir, file)
|
|
|
+ with open(file_path, "r", encoding="utf-8") as f:
|
|
|
+ content = f.read()
|
|
|
+
|
|
|
+ # 解析内容
|
|
|
+ sections = content.split("\n\n")
|
|
|
+ for section in sections:
|
|
|
+ if not section.strip() or "==== 以下ID请求失败 ====" in section:
|
|
|
+ continue
|
|
|
+
|
|
|
+ lines = section.strip().split("\n")
|
|
|
+ if len(lines) < 2:
|
|
|
+ continue
|
|
|
+
|
|
|
+ # 第一行是来源名
|
|
|
+ source_name = lines[0].strip()
|
|
|
+
|
|
|
+ # 提取标题和排名
|
|
|
+ title_ranks = {}
|
|
|
+ for line in lines[1:]:
|
|
|
+ if line.strip():
|
|
|
+ try:
|
|
|
+ # 提取序号和正文部分
|
|
|
+ match_num = None
|
|
|
+ title_part = line.strip()
|
|
|
+
|
|
|
+ # 处理格式 "数字. 标题"
|
|
|
+ if (
|
|
|
+ ". " in title_part
|
|
|
+ and title_part.split(". ")[0].isdigit()
|
|
|
+ ):
|
|
|
+ parts = title_part.split(". ", 1)
|
|
|
+ match_num = int(parts[0]) # 序号可能是排名
|
|
|
+ title_part = parts[1]
|
|
|
+
|
|
|
+ # 提取排名信息 "标题 (排名:1,2,3)"
|
|
|
+ ranks = []
|
|
|
+ if " (排名:" in title_part:
|
|
|
+ title, rank_str = title_part.rsplit(" (排名:", 1)
|
|
|
+ rank_str = rank_str.rstrip(")")
|
|
|
+ ranks = [
|
|
|
+ int(r)
|
|
|
+ for r in rank_str.split(",")
|
|
|
+ if r.strip() and r.isdigit()
|
|
|
+ ]
|
|
|
+ else:
|
|
|
+ title = title_part
|
|
|
+
|
|
|
+ # 如果没找到排名但有序号,则使用序号
|
|
|
+ if not ranks and match_num is not None:
|
|
|
+ ranks = [match_num]
|
|
|
+
|
|
|
+ # 确保排名列表不为空
|
|
|
+ if not ranks:
|
|
|
+ ranks = [99] # 默认排名
|
|
|
+
|
|
|
+ title_ranks[title] = ranks
|
|
|
+
|
|
|
+ except Exception as e:
|
|
|
+ print(f"解析标题行出错: {line}, 错误: {e}")
|
|
|
+
|
|
|
+ # 处理来源数据
|
|
|
+ DataProcessor._process_source_data(
|
|
|
+ source_name,
|
|
|
+ title_ranks,
|
|
|
+ time_info,
|
|
|
+ all_results,
|
|
|
+ title_info,
|
|
|
+ id_to_alias,
|
|
|
+ )
|
|
|
+
|
|
|
+ # 将结果从 {source_name: {title: [ranks]}} 转换为 {source_id: {title: [ranks]}}
|
|
|
+ id_results = {}
|
|
|
+ id_title_info = {}
|
|
|
+ for name, titles in all_results.items():
|
|
|
+ for id_value, alias in id_to_alias.items():
|
|
|
+ if alias == name:
|
|
|
+ id_results[id_value] = titles
|
|
|
+ id_title_info[id_value] = title_info[name]
|
|
|
+ break
|
|
|
+
|
|
|
+ return id_results, id_to_alias, id_title_info
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def _process_source_data(
|
|
|
+ source_name: str,
|
|
|
+ title_ranks: Dict,
|
|
|
+ time_info: str,
|
|
|
+ all_results: Dict,
|
|
|
+ title_info: Dict,
|
|
|
+ id_to_alias: Dict,
|
|
|
+ ) -> None:
|
|
|
+ """处理来源数据,更新结果和标题信息"""
|
|
|
+ if source_name not in all_results:
|
|
|
+ # 首次遇到此来源
|
|
|
+ all_results[source_name] = title_ranks
|
|
|
+
|
|
|
+ # 初始化标题信息
|
|
|
+ if source_name not in title_info:
|
|
|
+ title_info[source_name] = {}
|
|
|
+
|
|
|
+ # 记录每个标题的时间、次数和排名
|
|
|
+ for title, ranks in title_ranks.items():
|
|
|
+ title_info[source_name][title] = {
|
|
|
+ "first_time": time_info, # 记录首次时间
|
|
|
+ "last_time": time_info, # 最后时间初始同首次时间
|
|
|
+ "count": 1,
|
|
|
+ "ranks": ranks,
|
|
|
+ }
|
|
|
+
|
|
|
+ # 尝试反向生成ID
|
|
|
+ reversed_id = source_name.lower().replace(" ", "-")
|
|
|
+ id_to_alias[reversed_id] = source_name
|
|
|
+ else:
|
|
|
+ # 已有此来源,更新标题
|
|
|
+ for title, ranks in title_ranks.items():
|
|
|
+ if title not in all_results[source_name]:
|
|
|
+ all_results[source_name][title] = ranks
|
|
|
+ title_info[source_name][title] = {
|
|
|
+ "first_time": time_info, # 新标题的首次和最后时间都设为当前
|
|
|
+ "last_time": time_info,
|
|
|
+ "count": 1,
|
|
|
+ "ranks": ranks,
|
|
|
+ }
|
|
|
+ else:
|
|
|
+ # 已存在的标题,更新最后时间,合并排名信息并增加计数
|
|
|
+ existing_ranks = title_info[source_name][title]["ranks"]
|
|
|
+ merged_ranks = existing_ranks.copy()
|
|
|
+ for rank in ranks:
|
|
|
+ if rank not in merged_ranks:
|
|
|
+ merged_ranks.append(rank)
|
|
|
+
|
|
|
+ title_info[source_name][title][
|
|
|
+ "last_time"
|
|
|
+ ] = time_info # 更新最后时间
|
|
|
+ title_info[source_name][title]["ranks"] = merged_ranks
|
|
|
+ title_info[source_name][title]["count"] += 1
|
|
|
+
|
|
|
+
|
|
|
+class StatisticsCalculator:
|
|
|
+ """统计计算相关功能"""
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def count_word_frequency(
|
|
|
+ results: Dict,
|
|
|
+ word_groups: List[List[str]],
|
|
|
+ filter_words: List[str],
|
|
|
+ id_to_alias: Dict,
|
|
|
+ title_info: Optional[Dict] = None,
|
|
|
+ rank_threshold: int = CONFIG["RANK_THRESHOLD"],
|
|
|
+ ) -> Tuple[List[Dict], int]:
|
|
|
+ """
|
|
|
+ 统计词频,处理关联词和大小写不敏感,每个标题只计入首个匹配词组,并应用过滤词
|
|
|
+
|
|
|
+ Returns:
|
|
|
+ (stats, total_titles)元组
|
|
|
+ """
|
|
|
+ word_stats = {}
|
|
|
+ total_titles = 0
|
|
|
+ processed_titles = {} # 用于跟踪已处理标题 {source_id: {title: True}}
|
|
|
+
|
|
|
+ # 初始化title_info
|
|
|
+ if title_info is None:
|
|
|
+ title_info = {}
|
|
|
+
|
|
|
+ # 为每个词组创建统计对象
|
|
|
+ for group in word_groups:
|
|
|
+ group_key = " ".join(group)
|
|
|
+ word_stats[group_key] = {"count": 0, "titles": {}}
|
|
|
+
|
|
|
+ # 遍历所有标题并统计
|
|
|
+ for source_id, titles_data in results.items():
|
|
|
+ total_titles += len(titles_data)
|
|
|
+
|
|
|
+ # 初始化该来源的处理记录
|
|
|
+ if source_id not in processed_titles:
|
|
|
+ processed_titles[source_id] = {}
|
|
|
+
|
|
|
+ for title, source_ranks in titles_data.items():
|
|
|
+ # 跳过已处理的标题
|
|
|
+ if title in processed_titles.get(source_id, {}):
|
|
|
+ continue
|
|
|
+
|
|
|
+ title_lower = title.lower() # 转换为小写以实现大小写不敏感
|
|
|
+
|
|
|
+ # 检查是否包含任何过滤词
|
|
|
+ contains_filter_word = any(
|
|
|
+ filter_word.lower() in title_lower for filter_word in filter_words
|
|
|
+ )
|
|
|
+
|
|
|
+ # 如果包含过滤词,跳过这个标题
|
|
|
+ if contains_filter_word:
|
|
|
+ continue
|
|
|
+
|
|
|
+ # 按顺序检查每个词组
|
|
|
+ for group in word_groups:
|
|
|
+ group_key = " ".join(group)
|
|
|
+
|
|
|
+ # 检查是否有任何一个词在标题中
|
|
|
+ matched = any(word.lower() in title_lower for word in group)
|
|
|
+
|
|
|
+ # 如果匹配,增加计数并添加标题,然后标记为已处理
|
|
|
+ if matched:
|
|
|
+ word_stats[group_key]["count"] += 1
|
|
|
+ if source_id not in word_stats[group_key]["titles"]:
|
|
|
+ word_stats[group_key]["titles"][source_id] = []
|
|
|
+
|
|
|
+ # 获取标题信息
|
|
|
+ first_time = ""
|
|
|
+ last_time = ""
|
|
|
+ count_info = 1
|
|
|
+ ranks = source_ranks if source_ranks else []
|
|
|
+
|
|
|
+ if (
|
|
|
+ title_info
|
|
|
+ and source_id in title_info
|
|
|
+ and title in title_info[source_id]
|
|
|
+ ):
|
|
|
+ info = title_info[source_id][title]
|
|
|
+ first_time = info.get("first_time", "")
|
|
|
+ last_time = info.get("last_time", "")
|
|
|
+ count_info = info.get("count", 1)
|
|
|
+ if "ranks" in info and info["ranks"]:
|
|
|
+ ranks = info["ranks"]
|
|
|
+
|
|
|
+ # 添加带信息的标题
|
|
|
+ word_stats[group_key]["titles"][source_id].append(
|
|
|
+ {
|
|
|
+ "title": title,
|
|
|
+ "first_time": first_time,
|
|
|
+ "last_time": last_time,
|
|
|
+ "count": count_info,
|
|
|
+ "ranks": ranks,
|
|
|
+ }
|
|
|
+ )
|
|
|
+
|
|
|
+ # 标记该标题已处理,不再匹配其他词组
|
|
|
+ if source_id not in processed_titles:
|
|
|
+ processed_titles[source_id] = {}
|
|
|
+ processed_titles[source_id][title] = True
|
|
|
+ break # 找到第一个匹配的词组后退出循环
|
|
|
+
|
|
|
+ # 转换统计结果
|
|
|
+ stats = []
|
|
|
+ for group_key, data in word_stats.items():
|
|
|
+ titles_with_info = []
|
|
|
+ for source_id, title_list in data["titles"].items():
|
|
|
+ source_alias = id_to_alias.get(source_id, source_id)
|
|
|
+ for title_data in title_list:
|
|
|
+ title = title_data["title"]
|
|
|
+ first_time = title_data["first_time"]
|
|
|
+ last_time = title_data["last_time"]
|
|
|
+ count_info = title_data["count"]
|
|
|
+ ranks = title_data.get("ranks", [])
|
|
|
+
|
|
|
+ # 确保排名是有效的
|
|
|
+ if not ranks:
|
|
|
+ ranks = [99] # 使用默认排名
|
|
|
+
|
|
|
+ # 格式化排名信息
|
|
|
+ rank_display = StatisticsCalculator._format_rank_display(
|
|
|
+ ranks, rank_threshold
|
|
|
+ )
|
|
|
+
|
|
|
+ # 格式化时间信息
|
|
|
+ time_display = StatisticsCalculator._format_time_display(
|
|
|
+ first_time, last_time
|
|
|
+ )
|
|
|
+
|
|
|
+ # 格式化标题信息
|
|
|
+ formatted_title = f"[{source_alias}] {title}"
|
|
|
+ if rank_display:
|
|
|
+ formatted_title += f" {rank_display}"
|
|
|
+ if time_display:
|
|
|
+ formatted_title += f" - {time_display}"
|
|
|
+ if count_info > 1:
|
|
|
+ formatted_title += f" - {count_info}次"
|
|
|
+
|
|
|
+ titles_with_info.append(formatted_title)
|
|
|
+
|
|
|
+ stats.append(
|
|
|
+ {
|
|
|
+ "word": group_key,
|
|
|
+ "count": data["count"],
|
|
|
+ "titles": titles_with_info,
|
|
|
+ "percentage": (
|
|
|
+ round(data["count"] / total_titles * 100, 2)
|
|
|
+ if total_titles > 0
|
|
|
+ else 0
|
|
|
+ ),
|
|
|
+ }
|
|
|
+ )
|
|
|
+
|
|
|
+ # 按出现次数从高到低排序
|
|
|
+ stats.sort(key=lambda x: x["count"], reverse=True)
|
|
|
+
|
|
|
+ return stats, total_titles
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def _format_rank_display(ranks: List[int], rank_threshold: int) -> str:
|
|
|
+ """格式化排名显示"""
|
|
|
+ if not ranks:
|
|
|
+ return ""
|
|
|
+
|
|
|
+ # 排序排名并确保不重复
|
|
|
+ unique_ranks = sorted(set(ranks))
|
|
|
+ min_rank = unique_ranks[0]
|
|
|
+ max_rank = unique_ranks[-1]
|
|
|
+
|
|
|
+ # 根据最高排名判断使用哪种括号
|
|
|
+ if min_rank <= rank_threshold:
|
|
|
+ # 使用【】
|
|
|
+ if min_rank == max_rank:
|
|
|
+ return f"【{min_rank}】"
|
|
|
+ else:
|
|
|
+ return f"【{min_rank} - {max_rank}】"
|
|
|
+ else:
|
|
|
+ # 使用[]
|
|
|
+ if min_rank == max_rank:
|
|
|
+ return f"[{min_rank}]"
|
|
|
+ else:
|
|
|
+ return f"[{min_rank} - {max_rank}]"
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def _format_time_display(first_time: str, last_time: str) -> str:
|
|
|
+ """格式化时间显示,单次显示时间,多次显示时间范围"""
|
|
|
+ if not first_time:
|
|
|
+ return ""
|
|
|
+
|
|
|
+ if first_time == last_time or not last_time:
|
|
|
+ # 只有一个时间点,直接显示
|
|
|
+ return first_time
|
|
|
+ else:
|
|
|
+ # 有两个时间点,显示范围
|
|
|
+ return f"[{first_time} ~ {last_time}]"
|
|
|
+
|
|
|
+
|
|
|
+class ReportGenerator:
|
|
|
+ """报告生成相关功能"""
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def generate_html_report(
|
|
|
+ stats: List[Dict],
|
|
|
+ total_titles: int,
|
|
|
+ failed_ids: Optional[List] = None,
|
|
|
+ is_daily: bool = False,
|
|
|
+ ) -> str:
|
|
|
+ """
|
|
|
+ 生成HTML报告,包括失败的请求信息
|
|
|
+
|
|
|
+ Returns:
|
|
|
+ HTML文件路径
|
|
|
+ """
|
|
|
+ # 创建文件路径
|
|
|
+ if is_daily:
|
|
|
+ filename = "当日统计.html"
|
|
|
+ else:
|
|
|
+ filename = f"{TimeHelper.format_time_filename()}.html"
|
|
|
+
|
|
|
+ file_path = FileHelper.get_output_path("html", filename)
|
|
|
+
|
|
|
+ # HTML模板和内容生成
|
|
|
+ html_content = ReportGenerator._create_html_content(
|
|
|
+ stats, total_titles, failed_ids, is_daily
|
|
|
+ )
|
|
|
+
|
|
|
+ # 写入文件
|
|
|
+ with open(file_path, "w", encoding="utf-8") as f:
|
|
|
+ f.write(html_content)
|
|
|
+
|
|
|
+ return file_path
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def _create_html_content(
|
|
|
+ stats: List[Dict],
|
|
|
+ total_titles: int,
|
|
|
+ failed_ids: Optional[List] = None,
|
|
|
+ is_daily: bool = False,
|
|
|
+ ) -> str:
|
|
|
+ """创建HTML内容"""
|
|
|
+ # HTML头部
|
|
|
+ html = """
|
|
|
+ <!DOCTYPE html>
|
|
|
+ <html>
|
|
|
+ <head>
|
|
|
+ <meta charset="UTF-8">
|
|
|
+ <title>频率词统计报告</title>
|
|
|
+ <style>
|
|
|
+ body { font-family: Arial, sans-serif; margin: 20px; }
|
|
|
+ h1, h2 { color: #333; }
|
|
|
+ table { border-collapse: collapse; width: 100%; margin-top: 20px; }
|
|
|
+ th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
|
|
|
+ th { background-color: #f2f2f2; }
|
|
|
+ tr:nth-child(even) { background-color: #f9f9f9; }
|
|
|
+ .word { font-weight: bold; }
|
|
|
+ .count { text-align: center; }
|
|
|
+ .percentage { text-align: center; }
|
|
|
+ .titles { max-width: 500px; }
|
|
|
+ .source { color: #666; font-style: italic; }
|
|
|
+ .error { color: #d9534f; }
|
|
|
+ </style>
|
|
|
+ </head>
|
|
|
+ <body>
|
|
|
+ <h1>频率词统计报告</h1>
|
|
|
+ """
|
|
|
+
|
|
|
+ # 报告类型
|
|
|
+ if is_daily:
|
|
|
+ html += "<p>报告类型: 当日汇总</p>"
|
|
|
+
|
|
|
+ # 基本信息
|
|
|
+ now = TimeHelper.get_beijing_time()
|
|
|
+ html += f"<p>总标题数: {total_titles}</p>"
|
|
|
+ html += f"<p>生成时间: {now.strftime('%Y-%m-%d %H:%M:%S')}</p>"
|
|
|
+
|
|
|
+ # 失败的请求信息
|
|
|
+ if failed_ids and len(failed_ids) > 0:
|
|
|
+ html += """
|
|
|
+ <div class="error">
|
|
|
+ <h2>请求失败的平台</h2>
|
|
|
+ <ul>
|
|
|
+ """
|
|
|
+ for id_value in failed_ids:
|
|
|
+ html += f"<li>{id_value}</li>"
|
|
|
+ html += """
|
|
|
+ </ul>
|
|
|
+ </div>
|
|
|
+ """
|
|
|
+
|
|
|
+ # 表格头部
|
|
|
+ html += """
|
|
|
+ <table>
|
|
|
+ <tr>
|
|
|
+ <th>排名</th>
|
|
|
+ <th>频率词</th>
|
|
|
+ <th>出现次数</th>
|
|
|
+ <th>占比</th>
|
|
|
+ <th>相关标题</th>
|
|
|
+ </tr>
|
|
|
+ """
|
|
|
+
|
|
|
+ # 表格内容
|
|
|
+ for i, stat in enumerate(stats, 1):
|
|
|
+ html += f"""
|
|
|
+ <tr>
|
|
|
+ <td>{i}</td>
|
|
|
+ <td class="word">{stat['word']}</td>
|
|
|
+ <td class="count">{stat['count']}</td>
|
|
|
+ <td class="percentage">{stat['percentage']}%</td>
|
|
|
+ <td class="titles">{"<br>".join(stat['titles'])}</td>
|
|
|
+ </tr>
|
|
|
+ """
|
|
|
+
|
|
|
+ # 表格结尾
|
|
|
+ html += """
|
|
|
+ </table>
|
|
|
+ </body>
|
|
|
+ </html>
|
|
|
+ """
|
|
|
+
|
|
|
+ return html
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def send_to_feishu(
|
|
|
+ stats: List[Dict],
|
|
|
+ failed_ids: Optional[List] = None,
|
|
|
+ report_type: str = "单次爬取",
|
|
|
+ ) -> bool:
|
|
|
+ """
|
|
|
+ 将频率词统计结果发送到飞书
|
|
|
+
|
|
|
+ Returns:
|
|
|
+ 成功发送返回True,否则返回False
|
|
|
+ """
|
|
|
+ # 获取webhook URL,优先使用环境变量,其次使用配置中的URL
|
|
|
+ webhook_url = os.environ.get("FEISHU_WEBHOOK_URL", CONFIG["FEISHU_WEBHOOK_URL"])
|
|
|
+
|
|
|
+ # 检查webhook URL是否有效
|
|
|
+ if not webhook_url:
|
|
|
+ print(f"警告: FEISHU_WEBHOOK_URL未设置或无效,跳过发送飞书通知")
|
|
|
+ return False
|
|
|
+
|
|
|
+ headers = {"Content-Type": "application/json"}
|
|
|
+
|
|
|
+ # 获取总标题数
|
|
|
+ total_titles = sum(len(stat["titles"]) for stat in stats if stat["count"] > 0)
|
|
|
+
|
|
|
+ # 构建文本内容
|
|
|
+ text_content = ReportGenerator._build_feishu_content(stats, failed_ids)
|
|
|
+
|
|
|
+ # 构造消息体
|
|
|
+ now = TimeHelper.get_beijing_time()
|
|
|
+ payload = {
|
|
|
+ "msg_type": "text",
|
|
|
+ "content": {
|
|
|
+ "total_titles": total_titles,
|
|
|
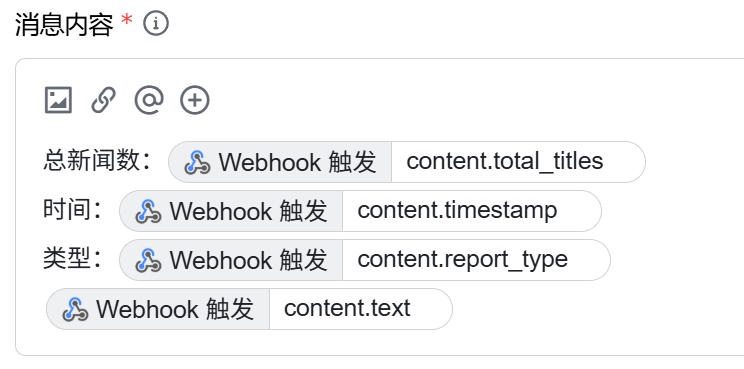
+ "timestamp": now.strftime("%Y-%m-%d %H:%M:%S"),
|
|
|
+ "report_type": report_type,
|
|
|
+ "text": text_content,
|
|
|
+ },
|
|
|
+ }
|
|
|
+
|
|
|
+ # 发送请求
|
|
|
+ try:
|
|
|
+ response = requests.post(webhook_url, headers=headers, json=payload)
|
|
|
+ if response.status_code == 200:
|
|
|
+ print(f"数据发送到飞书成功 [{report_type}]")
|
|
|
+ return True
|
|
|
+ else:
|
|
|
+ print(
|
|
|
+ f"发送到飞书失败 [{report_type}],状态码:{response.status_code},响应:{response.text}"
|
|
|
+ )
|
|
|
+ return False
|
|
|
+ except Exception as e:
|
|
|
+ print(f"发送到飞书时出错 [{report_type}]:{e}")
|
|
|
+ return False
|
|
|
+
|
|
|
+ @staticmethod
|
|
|
+ def _build_feishu_content(
|
|
|
+ stats: List[Dict], failed_ids: Optional[List] = None
|
|
|
+ ) -> str:
|
|
|
+ """构建飞书消息内容"""
|
|
|
+ text_content = ""
|
|
|
+
|
|
|
+ # 添加频率词统计信息
|
|
|
+ filtered_stats = [stat for stat in stats if stat["count"] > 0]
|
|
|
+ for i, stat in enumerate(filtered_stats):
|
|
|
+ word = stat["word"]
|
|
|
+ count = stat["count"]
|
|
|
+
|
|
|
+ text_content += f"【{word}】 : {count} 条\n"
|
|
|
+
|
|
|
+ # 添加相关标题
|
|
|
+ for j, title in enumerate(stat["titles"], 1):
|
|
|
+ text_content += f"{j}. {title}\n"
|
|
|
+
|
|
|
+ # 添加分割线
|
|
|
+ if i < len(filtered_stats) - 1:
|
|
|
+ text_content += f"\n{CONFIG['FEISHU_SEPARATOR']}\n\n"
|
|
|
+
|
|
|
+ if not text_content:
|
|
|
+ text_content = "无匹配频率词\n\n"
|
|
|
+
|
|
|
+ # 添加失败平台信息
|
|
|
+ if failed_ids and len(failed_ids) > 0:
|
|
|
+ if text_content and text_content != "无匹配频率词\n\n":
|
|
|
+ text_content += f"\n{CONFIG['FEISHU_SEPARATOR']}\n\n"
|
|
|
+
|
|
|
+ text_content += "失败平台:\n"
|
|
|
+ for i, id_value in enumerate(failed_ids, 1):
|
|
|
+ text_content += f"{i}. {id_value}\n"
|
|
|
+
|
|
|
+ return text_content
|
|
|
+
|
|
|
+
|
|
|
+class NewsAnalyzer:
|
|
|
+ """新闻分析主类"""
|
|
|
+
|
|
|
+ def __init__(
|
|
|
+ self,
|
|
|
+ request_interval: int = CONFIG["REQUEST_INTERVAL"],
|
|
|
+ feishu_report_type: str = CONFIG["FEISHU_REPORT_TYPE"],
|
|
|
+ rank_threshold: int = CONFIG["RANK_THRESHOLD"],
|
|
|
+ ):
|
|
|
+ """
|
|
|
+ 初始化新闻分析器
|
|
|
+
|
|
|
+ Args:
|
|
|
+ request_interval: 请求间隔(毫秒)
|
|
|
+ feishu_report_type: 飞书报告类型,可选值: "current"(当前爬取), "daily"(当日汇总), "both"(两者都发送)
|
|
|
+ rank_threshold: 排名显示阈值
|
|
|
+ """
|
|
|
+ self.request_interval = request_interval
|
|
|
+ self.feishu_report_type = feishu_report_type
|
|
|
+ self.rank_threshold = rank_threshold
|
|
|
+
|
|
|
+ # 判断是否在GitHub Actions环境中
|
|
|
+ self.is_github_actions = os.environ.get("GITHUB_ACTIONS") == "true"
|
|
|
+
|
|
|
+ # 设置代理
|
|
|
+ self.proxy_url = None
|
|
|
+ if not self.is_github_actions and CONFIG["USE_PROXY"]:
|
|
|
+ # 本地环境且启用代理时使用代理
|
|
|
+ self.proxy_url = CONFIG["DEFAULT_PROXY"]
|
|
|
+ print("本地环境,使用代理")
|
|
|
+ elif not self.is_github_actions and not CONFIG["USE_PROXY"]:
|
|
|
+ print("本地环境,未启用代理")
|
|
|
+ else:
|
|
|
+ print("GitHub Actions环境,不使用代理")
|
|
|
+
|
|
|
+ # 初始化数据获取器
|
|
|
+ self.data_fetcher = DataFetcher(self.proxy_url)
|
|
|
+
|
|
|
+ def generate_daily_summary(self) -> Optional[str]:
|
|
|
+ """
|
|
|
+ 生成当日统计报告
|
|
|
+
|
|
|
+ Returns:
|
|
|
+ HTML文件路径,如果生成失败则返回None
|
|
|
+ """
|
|
|
+ print("开始生成当日统计报告...")
|
|
|
+
|
|
|
+ # 读取当天所有标题
|
|
|
+ all_results, id_to_alias, title_info = DataProcessor.read_all_today_titles()
|
|
|
+
|
|
|
+ if not all_results:
|
|
|
+ print("没有找到当天的数据")
|
|
|
+ return None
|
|
|
+
|
|
|
+ # 计算标题总数
|
|
|
+ total_titles = sum(len(titles) for titles in all_results.values())
|
|
|
+ print(f"读取到 {total_titles} 个标题")
|
|
|
+
|
|
|
+ # 加载频率词和过滤词
|
|
|
+ word_groups, filter_words = DataProcessor.load_frequency_words()
|
|
|
+
|
|
|
+ # 统计词频
|
|
|
+ stats, total_titles = StatisticsCalculator.count_word_frequency(
|
|
|
+ all_results,
|
|
|
+ word_groups,
|
|
|
+ filter_words,
|
|
|
+ id_to_alias,
|
|
|
+ title_info,
|
|
|
+ self.rank_threshold,
|
|
|
+ )
|
|
|
+
|
|
|
+ # 生成HTML报告
|
|
|
+ html_file = ReportGenerator.generate_html_report(
|
|
|
+ stats, total_titles, is_daily=True
|
|
|
+ )
|
|
|
+ print(f"当日HTML统计报告已生成: {html_file}")
|
|
|
+
|
|
|
+ # 根据配置决定是否发送当日汇总到飞书
|
|
|
+ if self.feishu_report_type in ["daily", "both"]:
|
|
|
+ ReportGenerator.send_to_feishu(stats, [], "当日汇总")
|
|
|
+
|
|
|
+ return html_file
|
|
|
+
|
|
|
+ def run(self) -> None:
|
|
|
+ """执行新闻分析流程"""
|
|
|
+ # 输出当前时间信息
|
|
|
+ now = TimeHelper.get_beijing_time()
|
|
|
+ print(f"当前北京时间: {now.strftime('%Y-%m-%d %H:%M:%S')}")
|
|
|
+
|
|
|
+ # 检查FEISHU_WEBHOOK_URL是否存在
|
|
|
+ webhook_url = os.environ.get("FEISHU_WEBHOOK_URL", CONFIG["FEISHU_WEBHOOK_URL"])
|
|
|
+ if not webhook_url and not CONFIG["CONTINUE_WITHOUT_FEISHU"]:
|
|
|
+ print(
|
|
|
+ "错误: FEISHU_WEBHOOK_URL未设置或无效,且CONTINUE_WITHOUT_FEISHU为False,程序退出"
|
|
|
+ )
|
|
|
+ return
|
|
|
+
|
|
|
+ if not webhook_url:
|
|
|
+ print(
|
|
|
+ "警告: FEISHU_WEBHOOK_URL未设置或无效,将继续执行爬虫但不发送飞书通知"
|
|
|
+ )
|
|
|
+
|
|
|
+ print(f"飞书报告类型: {self.feishu_report_type}")
|
|
|
+ print(f"排名阈值: {self.rank_threshold}")
|
|
|
+
|
|
|
+ # 要爬取的网站ID列表
|
|
|
+ ids = [
|
|
|
+ ("toutiao", "今日头条"),
|
|
|
+ ("baidu", "百度热搜"),
|
|
|
+ ("wallstreetcn-hot", "华尔街见闻"),
|
|
|
+ ("thepaper", "澎湃新闻"),
|
|
|
+ ("bilibili-hot-search", "bilibili 热搜"),
|
|
|
+ ("cls-hot", "财联社热门"),
|
|
|
+ "tieba",
|
|
|
+ "weibo",
|
|
|
+ "douyin",
|
|
|
+ "zhihu",
|
|
|
+ ]
|
|
|
+
|
|
|
+ print(f"开始爬取数据,请求间隔设置为 {self.request_interval} 毫秒")
|
|
|
+
|
|
|
+ # 确保output目录存在
|
|
|
+ FileHelper.ensure_directory_exists("output")
|
|
|
+
|
|
|
+ # 爬取数据
|
|
|
+ results, id_to_alias, failed_ids = self.data_fetcher.crawl_websites(
|
|
|
+ ids, self.request_interval
|
|
|
+ )
|
|
|
+
|
|
|
+ # 保存标题到文件
|
|
|
+ title_file = DataProcessor.save_titles_to_file(results, id_to_alias, failed_ids)
|
|
|
+ print(f"标题已保存到: {title_file}")
|
|
|
+
|
|
|
+ # 从文件名中提取时间信息
|
|
|
+ time_info = os.path.basename(title_file).replace(".txt", "")
|
|
|
+
|
|
|
+ # 创建标题信息字典
|
|
|
+ title_info = {}
|
|
|
+ for source_id, titles_data in results.items():
|
|
|
+ title_info[source_id] = {}
|
|
|
+ for title, ranks in titles_data.items():
|
|
|
+ title_info[source_id][title] = {
|
|
|
+ "first_time": time_info,
|
|
|
+ "last_time": time_info,
|
|
|
+ "count": 1,
|
|
|
+ "ranks": ranks,
|
|
|
+ }
|
|
|
+
|
|
|
+ # 加载频率词和过滤词
|
|
|
+ word_groups, filter_words = DataProcessor.load_frequency_words()
|
|
|
+
|
|
|
+ # 统计词频
|
|
|
+ stats, total_titles = StatisticsCalculator.count_word_frequency(
|
|
|
+ results,
|
|
|
+ word_groups,
|
|
|
+ filter_words,
|
|
|
+ id_to_alias,
|
|
|
+ title_info,
|
|
|
+ self.rank_threshold,
|
|
|
+ )
|
|
|
+
|
|
|
+ # 根据配置决定发送哪种报告
|
|
|
+ if self.feishu_report_type in ["current", "both"]:
|
|
|
+ # 发送当前爬取数据到飞书
|
|
|
+ ReportGenerator.send_to_feishu(stats, failed_ids, "单次爬取")
|
|
|
+
|
|
|
+ # 生成HTML报告
|
|
|
+ html_file = ReportGenerator.generate_html_report(
|
|
|
+ stats, total_titles, failed_ids
|
|
|
+ )
|
|
|
+ print(f"HTML报告已生成: {html_file}")
|
|
|
+
|
|
|
+ # 生成当日统计报告
|
|
|
+ daily_html = self.generate_daily_summary()
|
|
|
+
|
|
|
+ # 在本地环境中自动打开HTML文件
|
|
|
+ if not self.is_github_actions and html_file:
|
|
|
+ file_url = "file://" + os.path.abspath(html_file)
|
|
|
+ print(f"正在打开HTML报告: {file_url}")
|
|
|
+ webbrowser.open(file_url)
|
|
|
+
|
|
|
+ if daily_html:
|
|
|
+ daily_url = "file://" + os.path.abspath(daily_html)
|
|
|
+ print(f"正在打开当日统计报告: {daily_url}")
|
|
|
+ webbrowser.open(daily_url)
|
|
|
+
|
|
|
+
|
|
|
+def main():
|
|
|
+ """程序入口点"""
|
|
|
+ # 初始化并运行新闻分析器
|
|
|
+ analyzer = NewsAnalyzer(
|
|
|
+ request_interval=CONFIG["REQUEST_INTERVAL"],
|
|
|
+ feishu_report_type=CONFIG["FEISHU_REPORT_TYPE"],
|
|
|
+ rank_threshold=CONFIG["RANK_THRESHOLD"],
|
|
|
+ )
|
|
|
+ analyzer.run()
|
|
|
+
|
|
|
+
|
|
|
+if __name__ == "__main__":
|
|
|
+ main()
|

 sansan
1 éve
sansan
1 éve
{kind=link}