
 kekezack
fbbbfe53c8
feat(data): 添加数据集图片资源
kekezack
fbbbfe53c8
feat(data): 添加数据集图片资源
|
1 天之前 | |
|---|---|---|
| .. | ||
| README.md | 1 天之前 | |
| metafile.yml | 1 天之前 | |
| ofa-base_finetuned_caption.py | 1 天之前 | |
| ofa-base_finetuned_refcoco.py | 1 天之前 | |
| ofa-base_finetuned_vqa.py | 1 天之前 | |
| ofa-base_zeroshot_vqa.py | 1 天之前 | |
| ofa-large_zeroshot_vqa.py | 1 天之前 | |
README.md
OFA
Abstract
In this work, we pursue a unified paradigm for multimodal pretraining to break the scaffolds of complex task/modality-specific customization. We propose OFA, a Task-Agnostic and Modality-Agnostic framework that supports Task Comprehensiveness. OFA unifies a diverse set of cross-modal and unimodal tasks, including image generation, visual grounding, image captioning, image classification, language modeling, etc., in a simple sequence-to-sequence learning framework. OFA follows the instruction-based learning in both pretraining and finetuning stages, requiring no extra task-specific layers for downstream tasks. In comparison with the recent state-of-the-art vision & language models that rely on extremely large cross-modal datasets, OFA is pretrained on only 20M publicly available image-text pairs. Despite its simplicity and relatively small-scale training data, OFA achieves new SOTAs in a series of cross-modal tasks while attaining highly competitive performances on uni-modal tasks. Our further analysis indicates that OFA can also effectively transfer to unseen tasks and unseen domains.
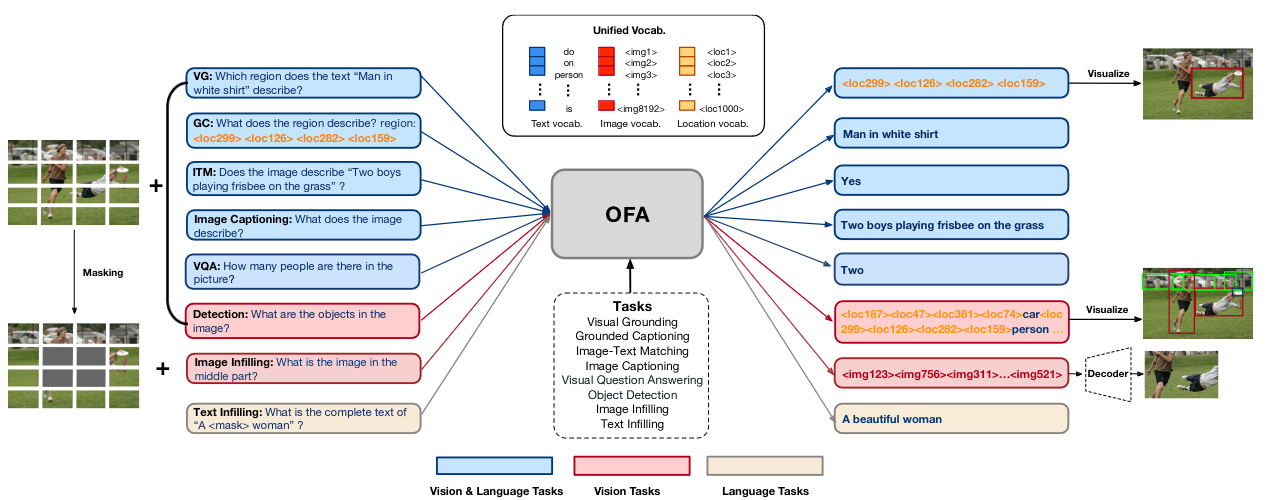
How to use it?
Use the model
from mmpretrain import inference_model
result = inference_model('ofa-base_3rdparty-finetuned_caption', 'demo/cat-dog.png')
print(result)
# {'pred_caption': 'a dog and a kitten sitting next to each other'}
Test Command
Prepare your dataset according to the docs.
Test:
python tools/test.py configs/ofa/ofa-base_finetuned_refcoco.py https://download.openmmlab.com/mmclassification/v1/ofa/ofa-base_3rdparty_refcoco_20230418-2797d3ab.pth
Models and results
Image Caption on COCO
| Model | Params (M) | BLEU-4 | CIDER | Config | Download |
|---|---|---|---|---|---|
ofa-base_3rdparty-finetuned_caption* |
182.24 | 42.64 | 144.50 | config | model |
*Models with * are converted from the official repo. The config files of these models are only for inference. We haven't reproduce the training results.*
Visual Grounding on RefCOCO
| Model | Params (M) | Accuracy (testA) | Accuracy (testB) | Config | Download |
|---|---|---|---|---|---|
ofa-base_3rdparty-finetuned_refcoco* |
182.24 | 90.49 | 83.63 | config | model |
*Models with * are converted from the official repo. The config files of these models are only for inference. We haven't reproduce the training results.*
Visual Question Answering on VQAv2
| Model | Params (M) | Accuracy | Config | Download |
|---|---|---|---|---|
ofa-base_3rdparty-finetuned_vqa* |
182.24 | 78.00 | config | model |
ofa-base_3rdparty-zeroshot_vqa* |
182.24 | 58.32 | config | model |
*Models with * are converted from the official repo. The config files of these models are only for inference. We haven't reproduce the training results.*
Citation
@article{wang2022ofa,
author = {Peng Wang and
An Yang and
Rui Men and
Junyang Lin and
Shuai Bai and
Zhikang Li and
Jianxin Ma and
Chang Zhou and
Jingren Zhou and
Hongxia Yang},
title = {OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence
Learning Framework},
journal = {CoRR},
volume = {abs/2202.03052},
year = {2022}
}